The OpenBB SDK (also known as OpenBB Platform) is developed as open-source (the code is available on https://github.com/OpenBB-finance/OpenBB) by the company Open BB. The OpenBB SDK provides programmatic access to a wide range of financial data sources from one place in a standard way.
The OpenBB SDK was developed to drive the OpenBB Workspace (See Introducing the new OpenBB Terminal ) which provides a customizable platform for financial analysts, investors and researchers that rivals traditional financial terminals without the steep costs.
By default, the OpenBB SDKwill attempt to download data from free sources such as Yahoo Finance but OpenBB SDK integrates with multiple other data sources as well such as , Alpha Vantage, FRED,FMP,SEC,etc .... In most OpenBB API platform calls, you can indicate a different data source - some of them free others requiring a separate subscription - allowing you to pull equities, options, crypto, forex and macroeconomic data using a single SDK.
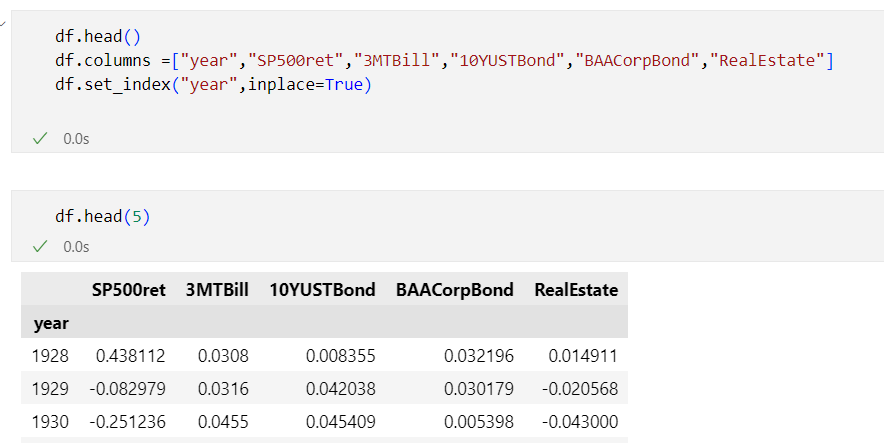
Since you can access both historical and real-time market data, OpenBB is ideal for backtesting and live trading strategies. The SDK is compatible with Jupyter Notebooks, Python scripts, and automated trading systems. I recently tested the OpenBB SDK as an alternative to Pandas_DataReader in Jupyter Notebooks, and it worked flawlessly.
I shared this Jupyter notebook on my Github repo:
https://github.com/jorisp/tradingnotebooks/blob/master/openbbdemo.ipynb
Please note that many of the code samples found in various articles and posts are no longer functional due to significant changes in the codebase. The shared Jupyter notebook has been tested with OpenBB 4.3.5 and Python 3.12.8.