Virtual entities in Dynamics CRM have been around for more than 4 years and were introduced with the 9.x release of Dynamics CRM Online. Virtual tables (entities) allow you to integrate external data into Dataverse without having the replicate the data or without having to write client side script to visualize the data. Virtual tables provide an abstraction layer which allow for real-time on-demand access to data wherever it resides, for end users it will look as if the data resides in Dataverse.
To be honest, I hadn't paid a lot of attention to virtual entities due to its limitations and due to the fact that there weren't a lot of improvements from Microsoft in it before 2021 - some of these limitations of virtual tables still exists like only organization owned tables, no auditing or change tracking, no queue support, a virtual table cannot represent an activity, etc... But a lot has changed in the last 12 months - for example CRUD support for virtual table providers went GA in March 2021 so I decided to take a look at it in the last couple of days. Another trigger was a blog post from @jukkan on Virtual Dataverse tables with no code, via Connectors which I marked already marked for review a couple of months ago.
Virtual Table Data Providers act as the glue between the external data and your virtual entities in Dataverse. There are currently 4 different flavors of the Virtual Table Data Providers: oData, custom-built using plugins, Cosmos DB and using the Power Platform Connector for SQL with a number of them still in preview. 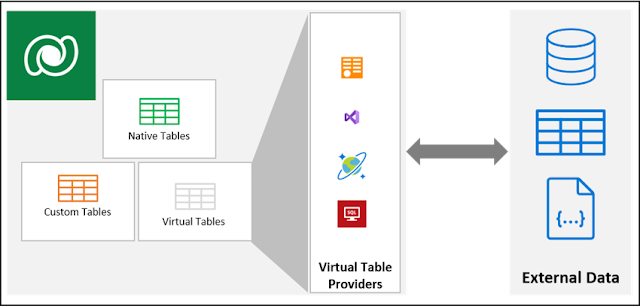
Dataverse ships with an
OOTB OData v4 Data Provider but I personally haven't seen any practical use case for this specific connector. So let's take a look at the current status of the 3 other data providers.
Custom Virtual Data Provider
Azure Cosmos DB SQL API Data Provider
Virtual Connector Data Provider
The
Virtual Connector Provider (VCP) for tabular connectors entered public preview in August 2021 (no GA date mentioned). The VCP preview currently supports only SQL Server (both on-premise and on-premise) but the release plan mentions that it will allow you to use Microsoft Dataverse virtual tables using multiple supported tabular connectors (e.g. SQL Server, OneDrive, Excel, SharePoint, etc...). Similar to the Cosmos DB Data Provider you will first need to install the solution from AppSource.
I got everything working using the walkthrough mentioned in
Create virtual tables using the virtual connector provider (preview) but overall the configuration experience is still confusing because you have to switch between the new and old solution designer experience (I think it even is safest to just do everything using the old solution designer).
I also noticed that when you use Azure SQL with the Virtual Connector Provider you might need to add the IP addresses from the Dataverse back-end servers to the Azure SQL whitelist - maybe because my Azure SQL is in a different tenant/subscription then the Dataverse environment.
After completing the configuration, the virtual tables initially did not work and when looking at the plugin trace logs - I noticed below exception. When adding both IP addresses (probably 2 back-end servers) to Azure SQL - everything started working.
The fact that you need to create a connection with all users in your organization is also something that Microsoft will change - a concern which is also shared in this blog post.
Dataverse virtual connector provider for SQL Server. Awesome? which also provides some interesting workarounds. I however think that is should be best that in a standard config - only the service principal that you used in the initial configuration should be given access to the SQL without a need to explicitly share the connection with everyone in the organization.
Summary
Virtual tables indeed show great promise but the Virtual Connector Provider is still a little bit to rough on the edges to use with confidence. As we near GA, I hope additional improvements will be made available especially around the security aspect.
References:
































